Cross-Model Benchmark
Run the same prompt through two or more models side by side and answer "which model is actually best for this task?" with data instead of vibes. For each model, measure latency, tokens (prompt + completion), and cost, capture the output, and — when the judge…
Runs on Jetty's managed sandbox. No setup. Free for your first 10 runs.
Real runs, real outputs.
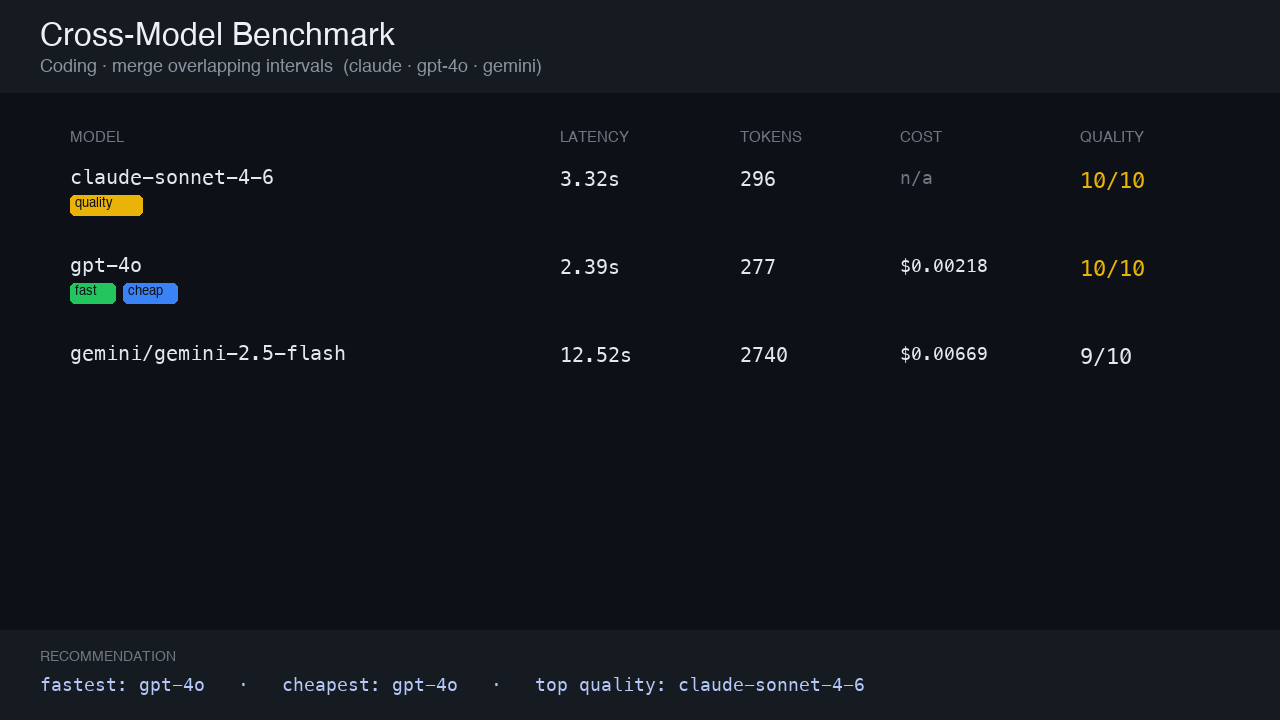
Coding prompt — merge intervals
Three models implement merge_intervals(). gpt-4o fastest + cheapest; claude and gpt tie at quality 10; gemini-2.5-flash verbose and slower.
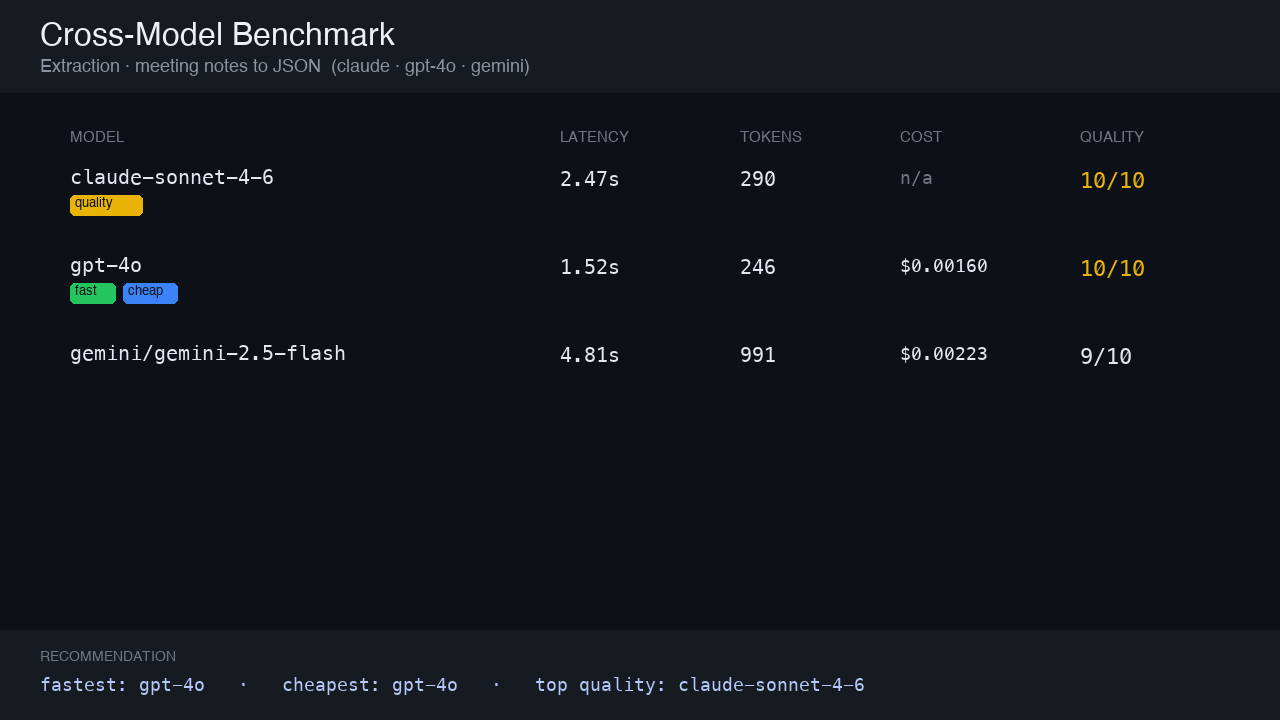
Extraction prompt — notes → JSON
Three models extract action items from meeting notes into JSON. gpt-4o fastest (1.52s) + cheapest; claude and gpt tie at quality 10.
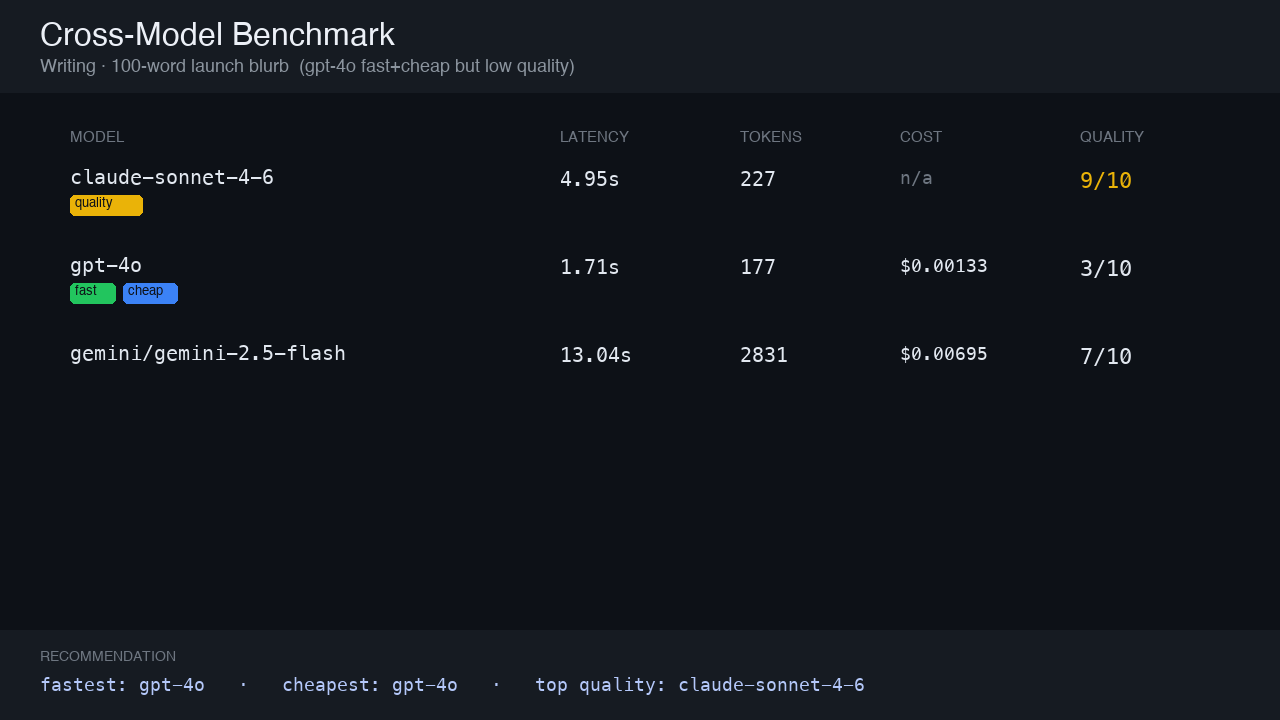
Writing prompt — launch blurb
The differentiating run: on a 100-word launch brief, gpt-4o was fastest + cheapest but scored only 3/10 (missed the no-hype constraint) while claude scored 9. Speed is…
8 steps · start to finish.
- 1Step 1
Environment Setup & Provider Preflight
▶python -m pip install --quiet "litellm>=1.40" mkdir -p "{{results_dir}}" echo "Provider keys present:" for k in ANTHROPIC_API_KEY OPENAI_API_KEY GEMINI_API_KEY OPENROUTER_API_KEY; do [ -n "${!k}" ] && echo " $k: SET" || echo " $k: (absent)" donePreflight (the dry-run, from the source skill): map each requested model to its provider and check the key is present. Models whose provider key is absent are reported as
skipped: no_keyand excluded — they do not abort the run. If zero models have a key, STOP and write a clear error (a benchmark needs at least one authed provider).Provider inference:
claude*/anthropic/*→ANTHROPIC_API_KEY;gpt*/o1*/openai/*→OPENAI_API_KEY;gemini*→GEMINI_API_KEY;openrouter/*→OPENROUTER_API_KEY. - 2Step 2
Resolve the Prompt
▶Use the first .txt/.md in /app/assets/; if none, use {{prompt}}. If both are empty, STOP with an error. Record the resolved prompt source in summary.md.
- 3Step 3
Run the Benchmark
▶Run the same prompt through every authed model, measuring latency, tokens, and cost. Errors are caught per-model and recorded, never raised.
- 4Step 4
Judge Quality (when `{{judge}}` is `true`)
▶For each successful output, ask the judge model to score it 0–10 on correctness, completeness, and clarity, returning strict JSON. Skip judging for models that errored.
- 5Step 5
Recommend & Write Outputs
▶ok = [r for r in results if r.get("ok")] def pick(seq, key, best=min): seq = [r for r in seq if r.get(key) is not None] return best(seq, key=lambda r: r[key]) if seq else None
- 6Step 6
Evaluate & Validate
▶Status · Criteria PASS · At least 2 models ran successfully; each successful model has latency + tokens recorded; benchmark.md has the table and a recommendation; (judge on) each successful model has…
- 7Step 7
Iterate (max 3 rounds)
▶If a model errored with a fixable cause, fix and retry only that model:
- 8Step 8
Write Executive Summary
▶Write {{results_dir}}/summary.md: