Test Design Review
Review the supplied tests for design quality against the guidelines catalogued below, and produce a precise, actionable review. Tests are executable specifications; the review judges how well each test reads as a specification — does it describe a scenario…
Runs on Jetty's managed sandbox. No setup. Free for your first 10 runs.
Real runs, real outputs.
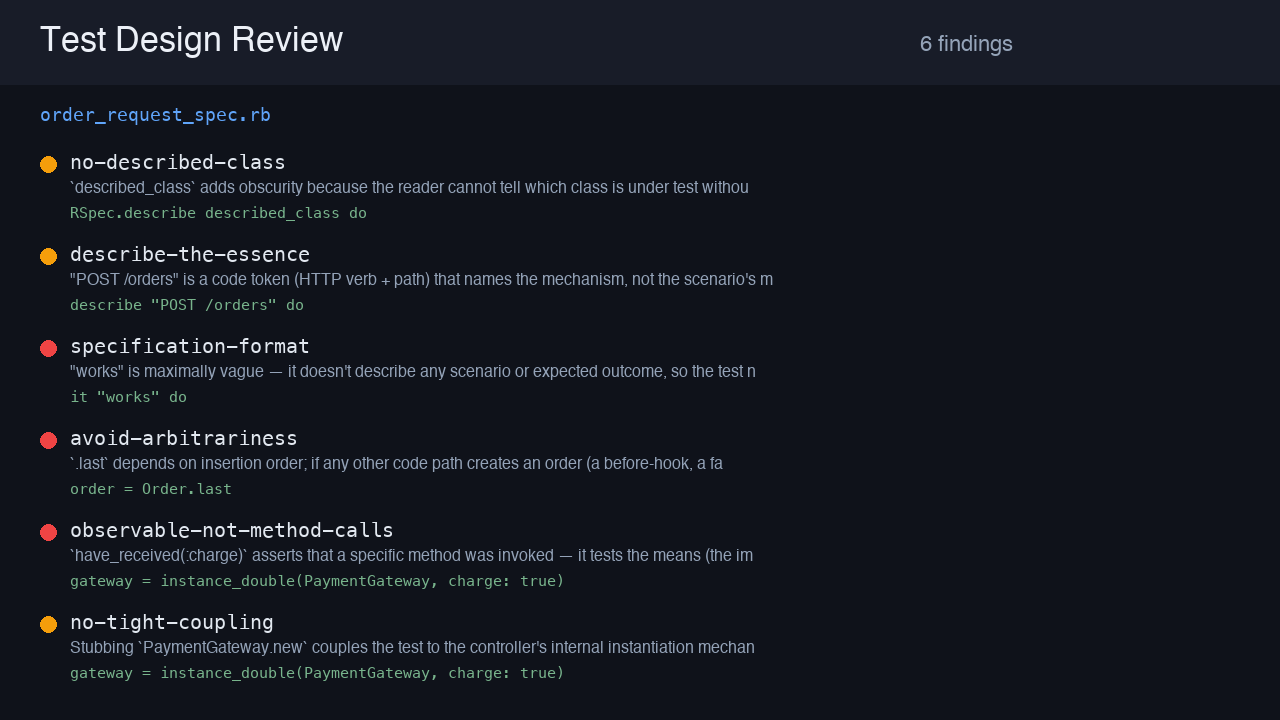
RSpec request spec
A request spec with a vague name, .last, a redundant assertion, a mock-based assertion, and described_class — 6 findings.
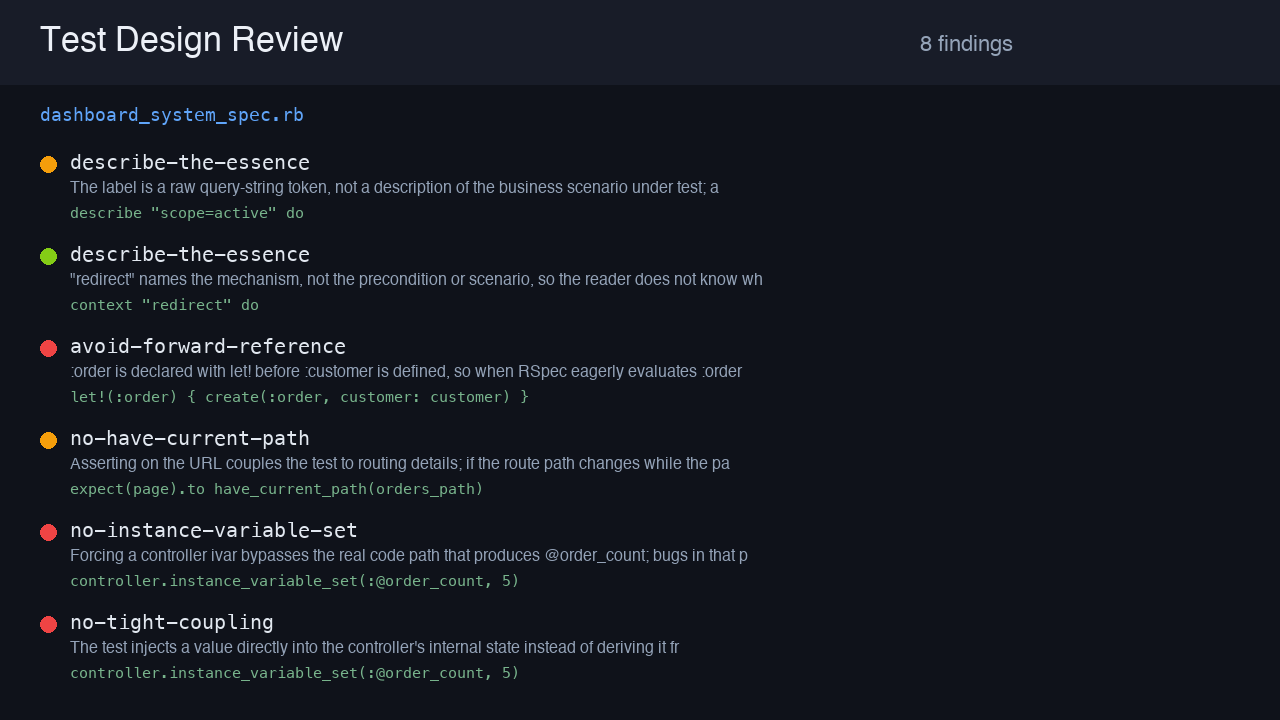
RSpec system spec
A feature spec with have_current_path, a forward reference, instance_variable_set, a cargo-culted wait: 3, and a code-token describe — 8 findings.
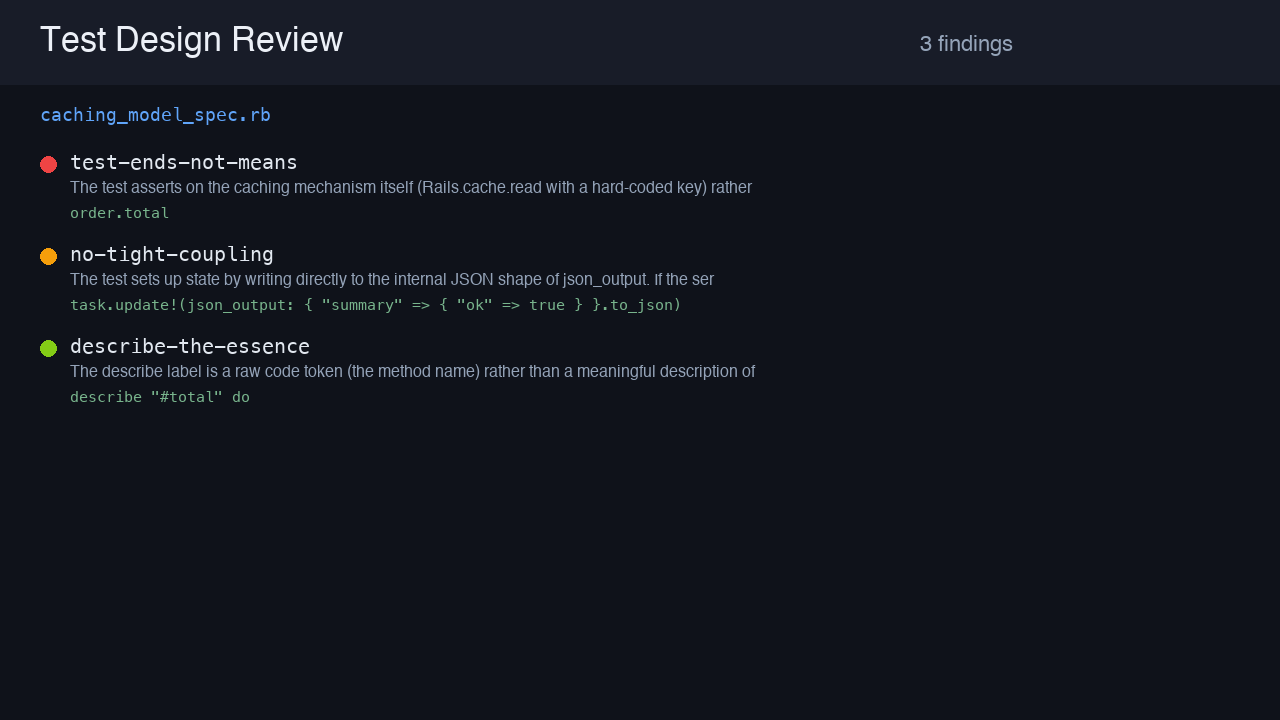
RSpec model spec
A model spec that asserts on the caching mechanism (Rails.cache.read) and couples to a JSON internal — the means-vs-ends smells. 3 findings.
8 steps · start to finish.
- 1Step 1
Environment Setup
▶mkdir -p "{{results_dir}}" shopt -s nullglob 2>/dev/null || true FILES=$(ls /app/assets/*.rb /app/assets/*_spec.rb /app/assets/*_test.rb /app/assets/*.rs /app/assets/*.py /app/assets/*.diff /app/assets/*.patch 2>/dev/null) echo "Files to review:"; echo "$FILES" [ -n "$FILES" ] || { echo "ERROR: no code files found in /app/assets"; exit 1; }Read each file in full before reviewing.
Guidelines Catalog (the review criteria)
Review every test against each guideline. Each has an
id(use it infindings.json), the rule, and a bad → good contrast.id Guideline The rule specification-formatSpecification format A test name should answer "in scenario X, what should happen?" — not vague ("it works correctly", "it handles errors"). behavior-not-implementationTest behavior, not implementation Assert on observable behavior, not internal/implementation details or hard-coded incidental values. describe-the-essenceDescribe the essence describe/contextstrings should capture the scenario's meaning ("rerunning only failed tests"), not a code token ("scope=failed").avoid-arbitrarinessAvoid arbitrariness Don't retrieve records with .first/.last(order-dependent, fragile). Use explicitchange/wherequeries instead.essential-not-incidentalAssert essentials, not incidentals Only assert what matters. Drop redundant assertions implied by others (e.g. be_successfulnext to a body assertion).one-level-of-abstractionDon't mix levels of abstraction A block should operate at one level; push incidental setup/details out of the essential flow. avoid-forward-referenceAvoid forward reference Don't reference a let/variable before it's defined; order definitions before use, or inline the value.no-have-current-pathDon't use have_current_pathToo coupled to the URL/implementation. Assert on what the user sees on the page. observable-not-method-callsAssert observable outcomes, not method calls Avoid mock assertions like expect(x).to have_received(:foo)(tests means). Assert the real end result. Stub only true externals.test-ends-not-meansTest ends, not means For caching/perf, assert the observable difference (e.g. zero extra DB queries), not the mechanism ( Rails.cache.read).high-level-of-abstractionMaintain a high level of abstraction Hide dense incidental details behind a well-named helper (defined after the test); show the essence. no-private-method-hacksDon't hack to test private methods Never send/public_sendto reach private methods — make the method public instead.no-tight-couplingDon't tightly couple to implementation Don't set up state via internal shapes ( json_output: {...}) when a behavioral input (exit_code: 0) expresses the scenario.arrange-act-assertUse Arrange / Act / Assert Structure the test into clear arrange, act, and assert phases. no-speculative-codingNo speculative coding Scrutinize cargo-culted choices (e.g. an unexplained wait: 3); remove what isn't justified.no-instance-variable-setNever instance_variable_setIf it seems necessary, that signals poor design — find it and suggest a specific refactor. no-described-classDon't use described_classIt adds obscurity; use the actual class name. The full bad/good examples for each guideline live in the source skill (linked in the frontmatter
origin). Apply the rule above; cite theidin findings. - 2Step 2
Review
▶For each file, read it fully, then walk the Guidelines Catalog top to bottom. For every violation, capture: the guideline id, the file, the line_start/line_end, the exact offending_code (quoted), a…
- 3Step 3
(reserved)
▶---
- 4Step 4
Write `findings.json`
▶One object per violation:
- 5Step 5
Write `review.md`
▶Group findings by guideline (matching the source skill's "group by guideline"). For each guideline with ≥1 finding, write a section: the guideline name, then each finding as the offending code…
- 6Step 6
Evaluate & Validate
▶Assign the review one status, then write validation_report.json.
- 7Step 7
Iterate (max 3 rounds)
▶If validation fails (invalid JSON, a finding missing fields, an unknown guideline id, or review.md not grouped), fix it and re-validate. Max 3 rounds; then surface the remaining issue in summary.md.
- 8Step 8
Write Executive Summary
▶Write {{results_dir}}/summary.md: